ChatGPT 画像生成AI GPT-Image-2の機能と活用方法
ChatGPTの新たな画像生成AI「GPT-Image-2(仮称)」の特徴や進化点、ストーリーボード生成や漫画・動画活用までの実務的な活用方法を整理。従来モデルとの違いや導入時の注意点も解説。

ChatGPT画像生成AIの進化概要
ChatGPTに搭載される画像生成AIは、近年大きな進化を遂げている。特に「GPT-Image-2(仮称)」と呼ばれる新モデルは、従来の画像生成機能と比較して表現力・構成力・指示追従性が大幅に向上している点が特徴である。従来は単一画像生成が中心であったが、現在は複数画像を連動させたコンテンツ生成が可能となっている。
GPT-Image-2の位置づけと背景
本モデルは正式発表前の段階で一部ユーザーに先行提供されており、調整段階のリリースと見られる。過去モデルであるGPT-Image-1.5からの進化として、構図理解やストーリー性のある出力が強化されている。特にテキスト指示に対する忠実性が向上しており、業務用途での再現性が高まっている。
従来モデルとの性能差
従来の画像生成AIでは、単発のビジュアル生成は可能であっても、複数カット間の一貫性維持が課題であった。GPT-Image-2では以下の点が改善されている。
- キャラクターの外観維持(顔・衣装・構図)
- シーンごとの連続性
- 複数画像間の物語構造
これにより、単なる素材生成から「コンテンツ生成」へと役割が変化している。
ストーリーボード生成機能の実用性
本モデルの中核的な進化はストーリーボード生成機能である。例えば、3×3グリッドでのシーン構成や映画的なカメラワーク指定など、映像制作に近い指示が可能となっている。これにより、企画段階のビジュアル設計を短時間で可視化できる。

漫画・ポスター生成への展開
生成されたストーリーボードは、そのまま漫画や映画ポスターに展開可能である。具体的には以下の流れで制作できる。
- キャラクター設定生成
- ストーリーボード生成
- シナリオ補完
- 漫画・ポスター化
この一連の工程を単一AIで完結できる点は、制作コスト削減に直結する。
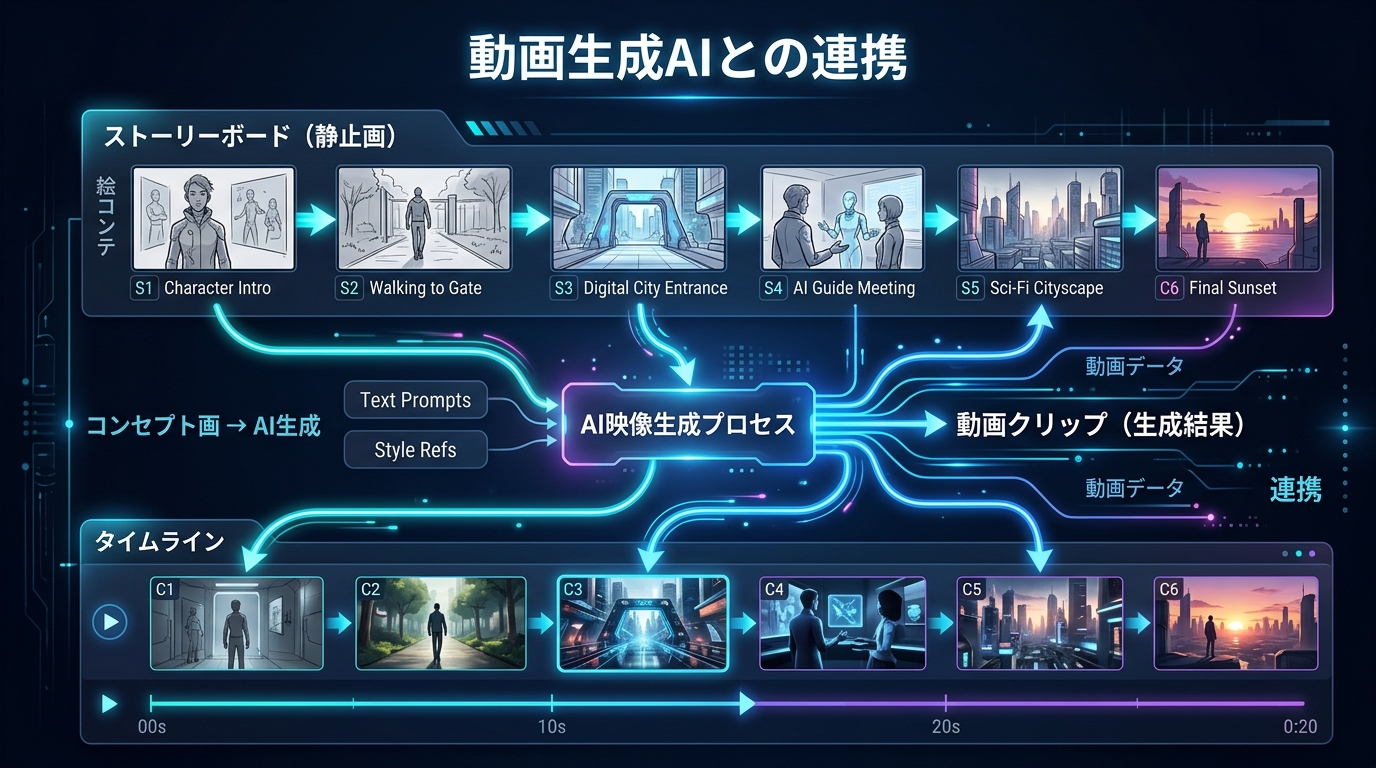
動画生成AIとの連携
生成したストーリーボードは動画生成AIと組み合わせることで、ショート動画制作にも活用できる。各シーンを動画化し接続することで、簡易的な映像作品を構築可能である。静止画から動画への変換工程を分離することで、柔軟な制作フローが実現される。
スタイル変換と表現制御
GPT-Image-2は同一構図を維持したまま、スタイルのみ変更することが可能である。例えば実写風からアニメ風への変換などが挙げられる。この機能により、同一コンテンツを複数フォーマットに最適化できるため、マーケティング用途での展開力が高い。
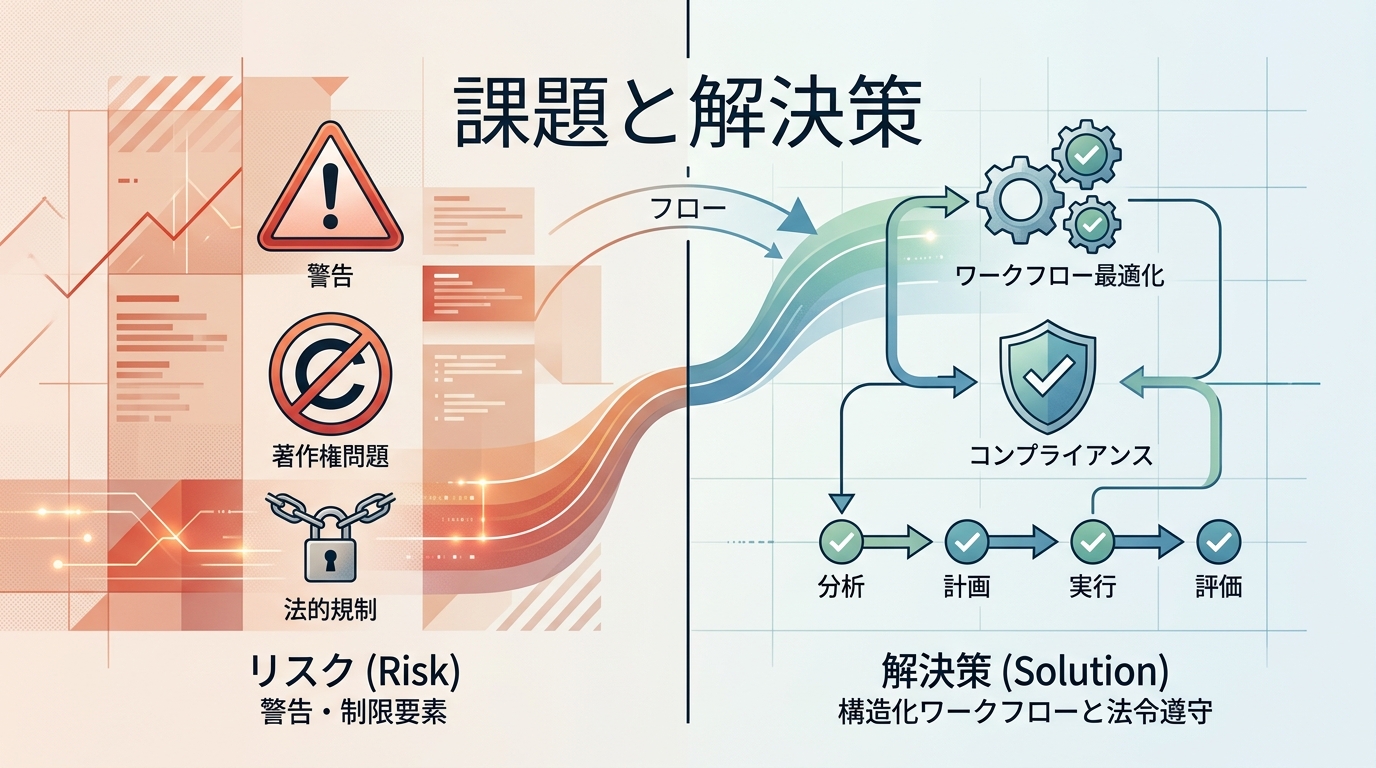
課題と解決策
一方で、以下の課題が存在する。
- 著作権・IPリスク
- 生成制限(暴力・性的表現)
- 品質の変動(リリース後の性能調整)
一般的な解決策としては、オリジナル設計の徹底、ガイドライン遵守、用途別のAI使い分けがある。実務では、制作工程を分離し、リスクのある領域を人間が監修する運用が有効である。
一例として、ファーストイノベーションのように、AI活用とマーケティング戦略を統合する支援サービスでは、生成AIの活用設計からリスク管理まで一体で対応するケースも存在する。
おすすめのイベント・クラウドファンディング


関連記事